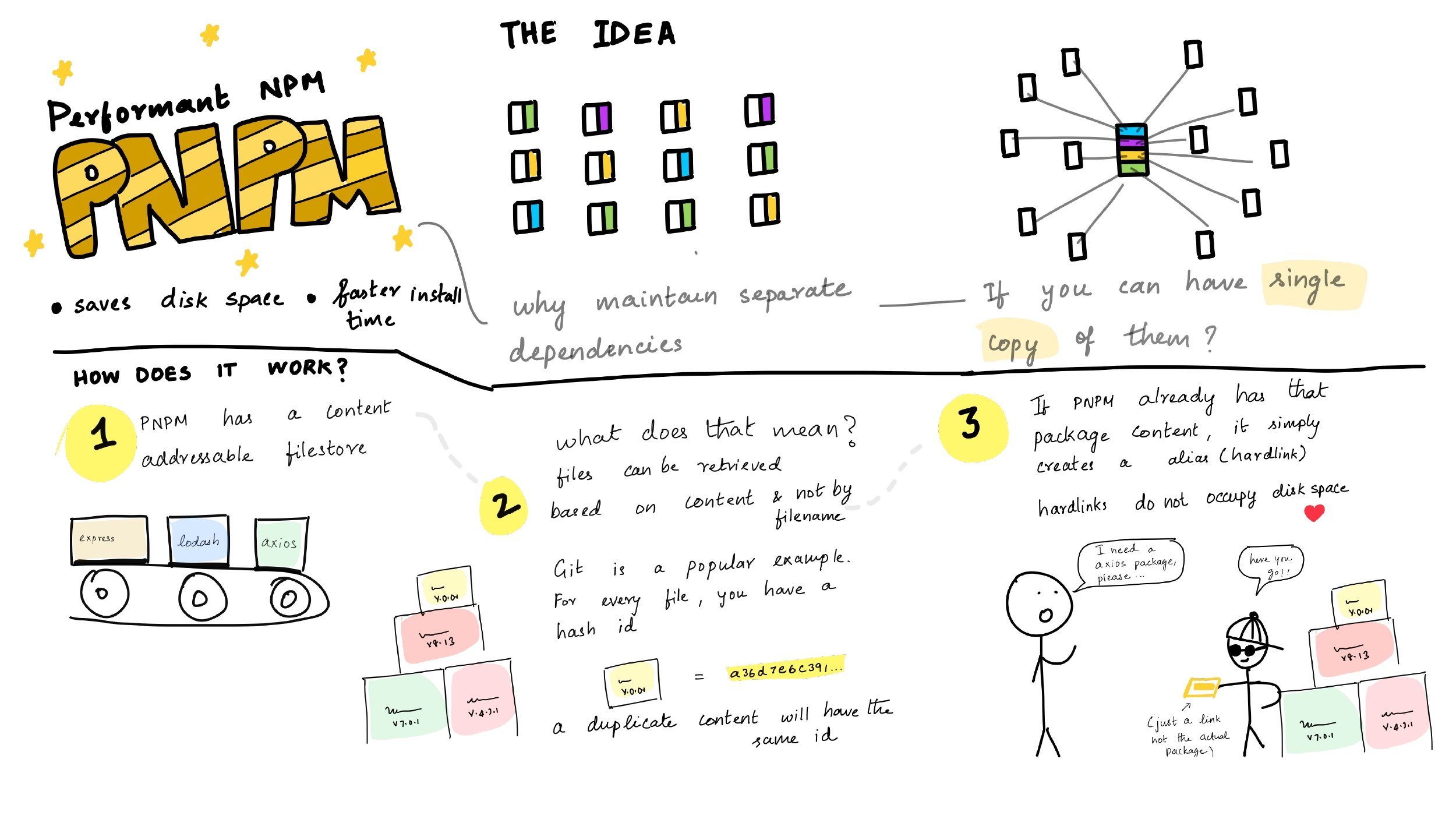
背景
前端项目发布到生产环境之后,线上问题几乎都需要用户投诉等渠道通知到开发人员,开发人员根据描述还原场景,定位问题再修复之,这样效率极低,影响用户体验和开发工作效率。
因此一些前端监控平台就应运而生了,目前比较主流的框架有:
为什么不用这些成熟的框架呢?首先这些框架都是收费的,费用不低,且存在数据泄漏的风险;其次平台二次开发受限,无法根据自身业务定制功能。所以搭建一套私有化的前端监控平台还是很有价值的,主要是能提高开发者排查问题,在用户投诉前发现问题并解决问题,减少用户投诉率。
整体架构
前端监控平台一般有四部分组成:日志采集、日志存储、日志分析、报警

日志采集
日志采集这一步主要是在用户端捕获各种错误信息以及一些环境信息,然后上报给服务端。
首先我们要明确平台需要哪些数据,除了最基本的错误信息之外,还需要项目信息、操作系统、浏览器版本和采样率等基础数据。
明确了数据之后就可以开始编写sdk了,下文将从错误信息、项目信息、操作系统、浏览器版本和采样率来分析如何采集。
错误信息
常见的错误类型分为五类:运行时报错、资源加载错误、HTTP请求异常、Promise异步错误、自定义报错。
运行时错误
运行时错误主要通过window.onerror或window.addEventListener('error')来捕获。
1
2
3
4
5
6
7
8
| var _onError = window.onerror;
window.onerror = function (message, filename, col, line, error) {
if (typeof _onError == "function") {
_onError(message, filename, col, line, error);
}
sendError(1, message, filename, col, line, error);
};
|
资源加载错误
资源加载错误和代码运行时错误可以获取方式类似,同样是使用addEventListener。区分是资源错误还是运行时错误,只需要判断e.target.localName或者e.message是否有值即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| window.addEventListener(
"error",
function (e) {
if (!e.message) {
var target = e.target;
var url = target.href || target.src;
var message = target.tagName + ' resource error' + url;
sendError(3, message, url, 0, 0, e);
} else {
sendError(1, e.message.split(':')[0], e.message.split(':')[1], e.colno , e.lineno , e.filename)
}
},
true
);
|
HTTP请求异常
HTTP请求异常——fetch(其余同理),在fetch函数内部挂入钩子,监听异常情况并记录错误信息(url, params, method, responseText,status,time)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| var _fetch = window.fetch;
window.fetch = function () {
var args = [].slice.call(arguments);
var result;
return new Promise(function (resolve, reject) {
_fetch
.apply(window, args)
.then(
function (res) {
result = res;
return res.clone().text();
},
function (e) {
setFetchError({
_args: args,
_parseError: e,
});
})
.then(
function (res) {
if (result && !result.ok) {
result._args = args;
result._responseText = res;
setFetchError(result);
}
resolve(res);
},
function (e) {
reject(e);
setFetchError({
_args: args,
_parseError: e,
});
}
);
});
};
};
function setFetchError(res) {
var args = res._args;
var method = (args[1] && args[1].method) || "GET";
var err = {
name: "HTTP ERROR [fetch]",
msg: args[0],
req: {
method: method,
url: args[0],
params: args[1] || "",
},
res: {
responseText: res._responseText,
status: res.status || 0,
statusText: res.statusText,
},
type: 2,
};
sendError(2, err.name, err.msg, 0, 0, err);
}
|
HTTP请求异常-jsonp请求
劫持document.createElement监听节点error事件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| var _createElement = document.createElement;
function setJSONError(el) {
el.addEventListener("error", function () {
sendError(4, "HTTP ERROR [jsonp]", el.src + "get", 0, 0);
});
}
document.createElement = function () {
var args = [].slice.call(arguments);
var result = _createElement.apply(document, args);
if (
args &&
args[0] &&
args[0].toLocaleUpperCase.indexOf("SCRIPT") > -1
) {
setJSONError(result);
}
return result;
};
|
Promise异步错误
Promise报错,监听unhandledrejection事件
1
2
3
4
5
6
7
8
9
10
11
12
| window.addEventListener('unhandledrejection', function (e, p) {
var result = e.reason;
if (typeof e.reason === 'string') {
result = {
name: e.reason.split(':')[0],
message: e.reason.split('--->')[0],
stack: e.reason
};
sendError(5, result.name, result.message, 0, 0, result);
}
});
|
自定义报错
自定义报错应用场景非常广泛,用于主动上报异常,平时业务代码中肯定存在部分异常处理的地方,比如try/catch的catch需要上报错误信息等等。自定义报错的实现就是暴露一个函数,供开发者主动调用。
1
2
3
4
5
6
7
8
9
|
function send(name, message, extra_data) {
sendError(0, name, message, 0, 0, '', extra_data);
}
|
错误信息格式化
错误信息捕获完之后,我们就需要将错误信息发送到服务端,那么在发我们之前我们就要先确定接口格式以及接口参数。也就是我们需要将错误信息做一个格式化。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| function sendError(type, message, filename, col, line, error) {
var _data = {
type: type,
col: col,
line: line,
extra: error || ''
}
if(type === 1) {
_data.name = message.split(':')[0];
_data.message = message.split(':')[1];
} else if(type === 0 || type === 2 || type === 3 || type === 4 || type === 5) {
_data.name = message;
_data.message = filename;
}
}
|
错误信息就通过类似的格式化一下就好了,当然这时候还不具备发送的条件,还需要接下来的一些辅助信息。
项目信息
采集异常的同时还需要将异常于信息关联起来,方便后台分析进行分析。对于项目信息的采集,提供两种方式:自动化采集和后台生成。
自动化采集
自动化采集就是通过sdk获取一些页面信息作为一个项目的唯一标识,比如页面title和url作为一个项目的标识,相同的title和url就认为是同一个项目。
1
2
3
4
5
6
7
8
9
|
function getProjectInfo() {
var title = document.title;
var url = location.href;
return { title, url };
}
|
后台生成
后台生成流程上要复杂一些,需要开发者在后台主动登记项目信息,由后台生成一个项目唯一标识如uuid,然后在html引入的时候带上这个uuid。
1
| <script id="monitor" uuid="12345" src="../monitor.js"></script>
|
1
2
3
4
5
| function getProjectInfo() {
var monitorDom = document.getElementById('monitor');
var uuid = monitorDom.getAttribute('uuid');
return uuid;
}
|
对比
两种采集项目信息的方式各有优缺点。自动化采集的方式比较方便不需要多余的流程,但是不适合一些动态的场景,比如搜索页面它的title和url是不固定的,这样就会导致线上会有很多项目难以聚合;后台生成的方式除了麻烦一些,就没有自动化采集的缺点,它会根据uuid去标识项目的唯一性,不受页面的title和url的影响。
1
2
3
|
<title>搜索结果xxx</title>
|
操作系统
操作系统信息就比较简单了,通过navigator.userAgent来获取。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
function getOsInfo() {
var userAgent = navigator.userAgent.toLowerCase();
var name = 'Unknown';
var version = 'Unknown';
if (userAgent.indexOf('win') > -1) {
name = 'Windows';
if (userAgent.indexOf('windows nt 5.0') > -1) {
version = 'Windows 2000';
} else if (userAgent.indexOf('windows nt 5.1') > -1 || userAgent.indexOf('windows nt 5.2') > -1) {
version = 'Windows XP';
} else if (userAgent.indexOf('windows nt 6.0') > -1) {
version = 'Windows Vista';
} else if (userAgent.indexOf('windows nt 6.1') > -1 || userAgent.indexOf('windows 7') > -1) {
version = 'Windows 7';
} else if (userAgent.indexOf('windows nt 6.2') > -1 || userAgent.indexOf('windows 8') > -1) {
version = 'Windows 8';
} else if (userAgent.indexOf('windows nt 6.3') > -1) {
version = 'Windows 8.1';
} else if (userAgent.indexOf('windows nt 6.2') > -1 || userAgent.indexOf('windows nt 10.0') > -1) {
version = 'Windows 10';
} else {
version = 'Unknown';
}
} else if (userAgent.indexOf('iphone') > -1) {
name = 'Iphone';
} else if (userAgent.indexOf('mac') > -1) {
name = 'Mac';
} else if (userAgent.indexOf('x11') > -1 || userAgent.indexOf('unix') > -1 || userAgent.indexOf('sunname') > -1 || userAgent.indexOf('bsd') > -1) {
name = 'Unix';
} else if (userAgent.indexOf('linux') > -1) {
if (userAgent.indexOf('android') > -1) {
name = 'Android';
} else {
name = 'Linux';
}
} else {
name = 'Unknown';
}
return { name, version };
}
|
浏览器版本
浏览器版本和操作系统一样,依旧是通过navigator.userAgent来获取,可以根据自身业务来制定需要浏览器的哪些信息,这里提供一个简版的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
function getBrowser() {
var UserAgent = navigator.userAgent.toLowerCase();
var browserInfo = {};
var browserArray = {
IE: window.ActiveXObject || "ActiveXObject" in window,
Chrome: UserAgent.indexOf('chrome') > -1 && UserAgent.indexOf('safari') > -1,
Firefox: UserAgent.indexOf('firefox') > -1,
Opera: UserAgent.indexOf('opera') > -1,
Safari: UserAgent.indexOf('safari') > -1 && UserAgent.indexOf('chrome') == -1,
Edge: UserAgent.indexOf('edge') > -1,
QQBrowser: /qqbrowser/.test(UserAgent),
WeixinBrowser: /MicroMessenger/i.test(UserAgent)
};
for (var i in browserArray) {
if (browserArray[i]) {
var versions = '';
if (i == 'IE') {
versions = UserAgent.match(/(msie\s|trident.*rv:)([\w.]+)/)[2];
} else if (i == 'Chrome') {
for (var mt in navigator.mimeTypes) {
if (navigator.mimeTypes[mt]['type'] == 'application/360softmgrplugin') {
i = '360';
}
}
versions = UserAgent.match(/chrome\/([\d.]+)/)[1];
} else if (i == 'Firefox') {
versions = UserAgent.match(/firefox\/([\d.]+)/)[1];
} else if (i == 'Opera') {
versions = UserAgent.match(/opera\/([\d.]+)/)[1];
} else if (i == 'Safari') {
versions = UserAgent.match(/version\/([\d.]+)/)[1];
} else if (i == 'Edge') {
versions = UserAgent.match(/edge\/([\d.]+)/)[1];
} else if (i == 'QQBrowser') {
versions = UserAgent.match(/qqbrowser\/([\d.]+)/)[1];
}
browserInfo.type = i;
browserInfo.versions = parseInt(versions);
}
}
return browserInfo;
}
|
采样率
采样率即异常上报的频率,0.1的采样率即出现10个报错上报1个。为什么需要采样率呢?假设项目的用户量很大,QPS达到几万或者几百万几千万,刚好这时候出现了一个线上错误,全部发送到服务端肯定会打爆带宽导致服务器崩溃,这时候有一个采样率就可以帮我们消除一部分请求量缓解服务器压力。sdk实现采样率这个逻辑也蛮简单,Math.random()就可以实现,然后在发送前取一次随机数,如果随机数小于采样率则上报。
1
2
3
4
| var samplingRate = 0.1;
if(Math.random() <= samplingRate) {
}
|
上报异常
至此需要上报的信息我们已经获取到了,接下去sdk就只要上报异常即可。上报方式就是发送携带错误信息的http请求(由于上报内容过多,建议使用post请求)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| var url = 'http://127.0.0.1:3000/';
var samplingRate = 0.1;
function sendInfo(_data) {
if(Math.random() > samplingRate) return;
var _data = [];
for(let key in data) {
_data.push(key + '=' + data[key]);
}
var xhr = new XMLHttpRequest();
xhr.onreadystatechange = function() {
if(xhr.readySatet === 4) {
}
}
xhr.open('POST', url);
xhr.send(_data.join('&'));
}
|
服务端
服务端的工作是对上报的异常数据进行分析、聚合、报警,并存入合适的数据库。整体架构如下图:
服务端接口
服务端接口的作用是接收数据,并推入消息队列,用node模拟一个接口。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| const Koa = require('koa');
const app = new Koa();
const Router = require('koa-router');
const router = new Router();
const bodyParser = require('koa-bodyparser')
app.use(bodyParser())
router.get('/senderror', async (ctx) => {
const params = ctx.request.body;
ctx.body = {
code: 0,
msg: '',
data: ''
}
})
app.use(router.routes())
app.listen(3000);
|
消息队列
有后端开发经验的同学可能会有一个想法,为什么不在接受异常数据的接口做分析并入库呢?这种方式显然是不合理的,当接口并发量巨大的时候,会导致数据库的访问量也巨大,从而导致数据库服务器崩溃,间接导致接口服务挂掉。所以我们需要将接收到的数据推送消息队列,主要就是为了削峰,消息队列服务能够支撑的并发是很高的,基本不用担心被打挂。
常见的消息队列主要有RabbitMQ和Kafka。它们两者的区别可以自行去【消息队列的区别】研究,大概介绍一下:
- kafka号称大数据杀手,所以它的吞吐量高,时效为ms,可用性高,但是消费失败不支持重试。
- rabbitmq健壮稳定,功能比较齐全,就是吞吐量不是很高。
本文就采取吞吐量高的kafka作为消息队列来做削峰处理,node也有相关的npm包支持(链接kafkajs)。
使用kafkajs的步骤:
配置连接到kafka服务,并提供消费者(producer)和生产者(consumer)对象。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
const { Kafka } = require('kafkajs')
const kafka = new Kafka({
clientId: 'my-app',
brokers: ['kafka1:9092', 'kafka2:9092']
})
const producer = kafka.producer()
const consumer = kafka.consumer({ groupId: 'test-group' })
const run = async () => {
await producer.connect()
}
run().catch(console.error);
module.exports = { producer, consumer };
|
生产者推送数据(即sendError接口)
1
2
3
4
5
6
7
8
9
10
11
12
13
|
const { producer } = require('kafkaScripts.js');
router.get('/senderror', async (ctx) => {
const params = ctx.request.body;
await producer.send({
topic: 'test-topic',
messages: [
{ value: JSON.stringify(params) },
],
})
})
|
消费者订阅数据,用于后续的存储、分析、报警等。
1
2
3
4
5
6
7
8
9
10
11
| const { consumer } = require('kafkaScripts.js');
await consumer.connect()
await consumer.subscribe({ topic: 'test-topic', fromBeginning: true })
await consumer.run({
eachMessage: async ({ topic, partition, message }) => {
}
})
|
异常聚合
异常聚合算是整个系统中最重要的一环,因为当线上项目出现报错时,往往是批量的上报同一个错误,不做聚合的话同一个错误就会出现成千上万次。事实上我们并不需要这么多错误信息,大多数情况下开发者只需要记录一条错误信息和出现次数就可以了,这样就可以分析出当前错误的影响面和错误的具体位置及原因。
对于聚合能做的事情有很多,当然也没法100%的聚合成功。为什么呢?比如有这么一个接口异常http://xxx.com/id/1/name/xxx,参数千变万化如何才能将这类异常完全聚合是一件很麻烦的事件,这过程可能涉及到文本相似度匹配、机器学习等等手段,所以聚合这件事我们可以根据自身业务慢慢去调整。
本文用最简单的运行时异常来举例如何聚合:
- 分析运行时异常的特点。运行时异常有一个很明显的特点,那就是有发生错误代码的行列号。
- 行列号和报错文件名可以作为错误聚合的唯一标识。报错信息可以变化(比如上面截图的a,它可以是一个变量,比如数组的下标等),而报错文件的行列号一定是唯一的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
const data = params;
if(data.type === 1) {
const { filename, col, row, uuid } = data;
const result = select(uuid, filename, col, row);
if(result && result.length) {
} else {
}
}
|
触发报警
异常报警其实和异常聚合一样,没法做到绝对的精准,也就是存在一定的误报率。我们只有尽可能去做的精准,想要精准还是需要机器学习等智能手段的帮助。这里推荐一种报警规则:错误率+自定义报警规则(不适合所有场景)。
错误率 = 错误数/ (总错误数 + pv人数);
自定义报警:n分钟触发m个错误数,错误总数达到x个等等。
报警方式:邮件或者其他通信工具。
数据存储
对于存储方案,我们对比下常见的几种:elk、mongodb、hbase、mysql。mysql作为关系型数据库,一般将持久化的数据存在mysql,比如异常统计和报表等数据。另外三个则作为日志存储,用于实时数据的查询和插入,对性能要求极高。
|
数据规模 |
查询性能 |
写入性能 |
复杂查询、检索功能 |
| MongoDB |
好 |
好 |
一般 |
好 |
| ES |
一般 |
一般 |
差 |
极好 |
| HBase |
极好 |
差 |
好 |
一般 |
三个数据库对比下来,mongodb的表现较好且搭建成本不高,因此数据存储推荐mongodb+mysql结合的形式。mongodb作为实时数据的存储,mysql作为报表数据的存储。
可视化平台
可视化平台作为项目开发人员唯一接触的东西,核心功能包括:错误列表、错误详情、统计图、设备信息等,可以根据自身需求定制。下面参考下webfunny的页面:
错误列表
- 异常分布图
- 错误列表,展示错误文件、事件数、错误类型、时间、错误信息、设备信息
错误详情
错误详情,根据列表中的错误信息聚合查询出来的信息,包括错误发生页面、发生次数、影响用户、设备信息及分布情况、错误堆栈信息、sourcemap等。
总结
到这里,一个前端异常异常监控平台的大致流程是完成了。
当然想要完美的平台那还早,这只是最初的一个版本,文中涉及到的每一个环节都还是可以再深入研究和扩展。
其中还有一些完善的地方,比如没有细讲sourcemap,它对于开发排查问题有着极大的帮助;还有用户行为分析,记录用户做了哪些操作才触发的错误。